

搞懂缓存机制,Token 消耗直降 80%
从 Transformer KV 缓存原理到 Claude Code 源码逆向,一套完整的省钱方案
每次打开 Claude Code,敲第一句话,2%~10% 的套餐额度就没了。午休回来继续干活,又一句话,10% 的额度蒸发。
Token 到底花在哪了?
我们带着这个疑问,在本地用 Gemma 4 跑小模型做实验,逆向 Claude Code 源码,最终发现了一整套精密的缓存工程。理解了这套机制,同样的套餐可以多撑 3-5 倍。
先拿 Ollama 在 Mac (Apple Silicon, 16GB) 上跑 Gemma 4 (8B 总参数,9.6GB 模型),写了个测试脚本做多轮对话:先喂一篇 670 token 的文章,然后连续追问 5 个问题。

Prompt 处理 生成 总耗时
Turn 1 (喂文章): 24,458ms 5,095ms (68 tok) 34s
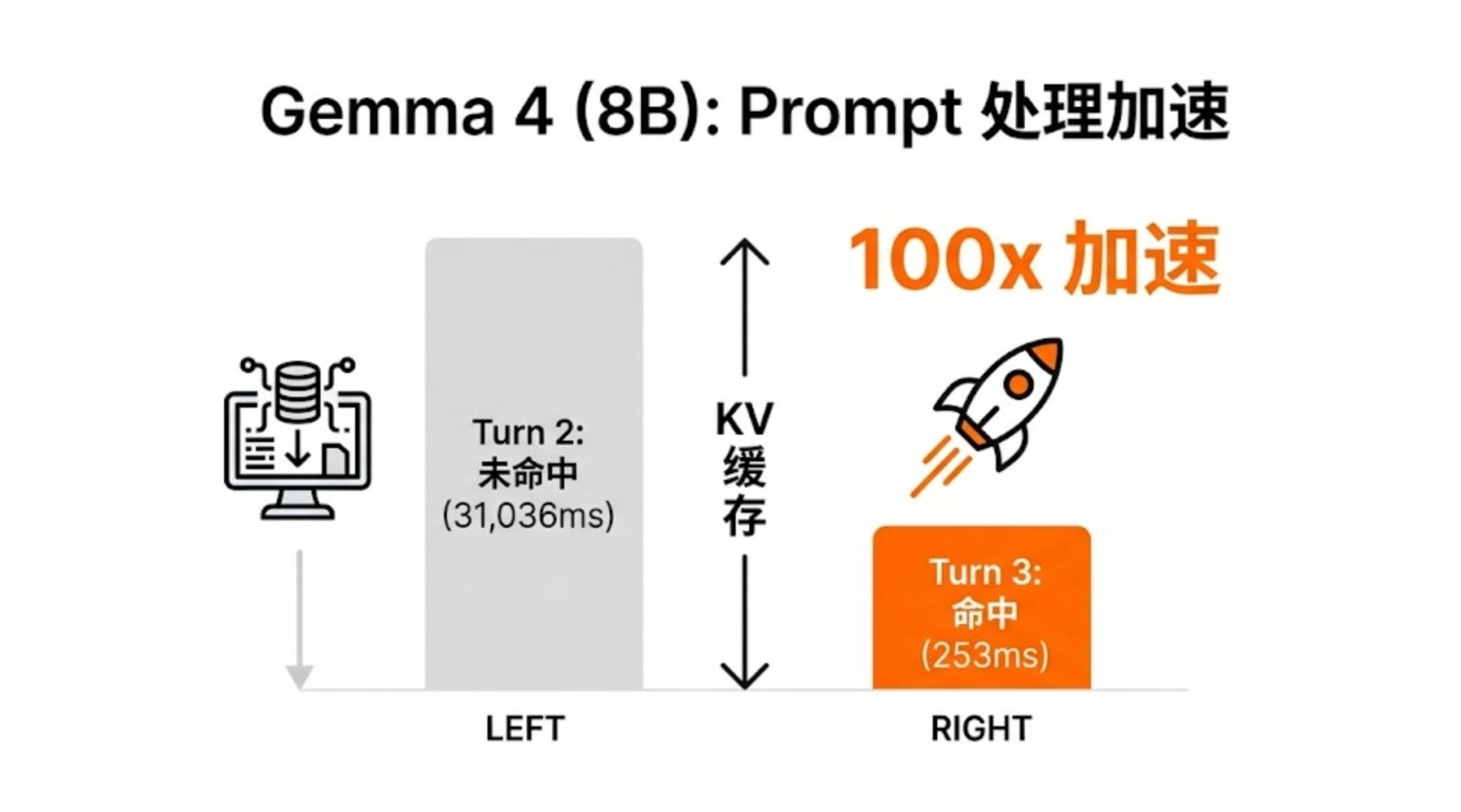
Turn 2 (追问1): 31,036ms 22,653ms (365 tok) 58s
Turn 3 (追问2): 253ms !! 2,511ms (46 tok) 3.8s
Turn 4 (追问3): 203ms 2,029ms (36 tok) 3.0s
Turn 5 (追问4): 165ms 1,870ms (37 tok) 2.4s
Turn 6 (追问5): 176ms 1,235ms (26 tok) 1.8s
Turn 2 到 Turn 3,prompt 处理从 31 秒直降到 0.25 秒 -- 100 倍加速。生成速度始终稳定在 13-20 tok/s,丝毫不受影响。
加速只发生在"消化输入"阶段,和"吐出回答"无关。
对比小模型 Qwen3.5 (0.8B):
Gemma 4 (4.5B active) Qwen3.5 (0.8B)
未命中 ~25,000ms ~566ms
命中 ~170ms ~173ms
加速比 148x 3.3x
命中时速度 3,000-5,000 tok/s 3,200-3,900 tok/s
模型越大,KV 计算越昂贵,缓存收益越大。命中时两个模型速度几乎一样 -- 都是从内存读取。

Transformer 注意力机制核心公式:
Attention(Q, K, V) = softmax(Q . K^T / sqrt(d)) . V
三个角色:
| 角色 | 含义 | 能否缓存 |
|---|---|---|
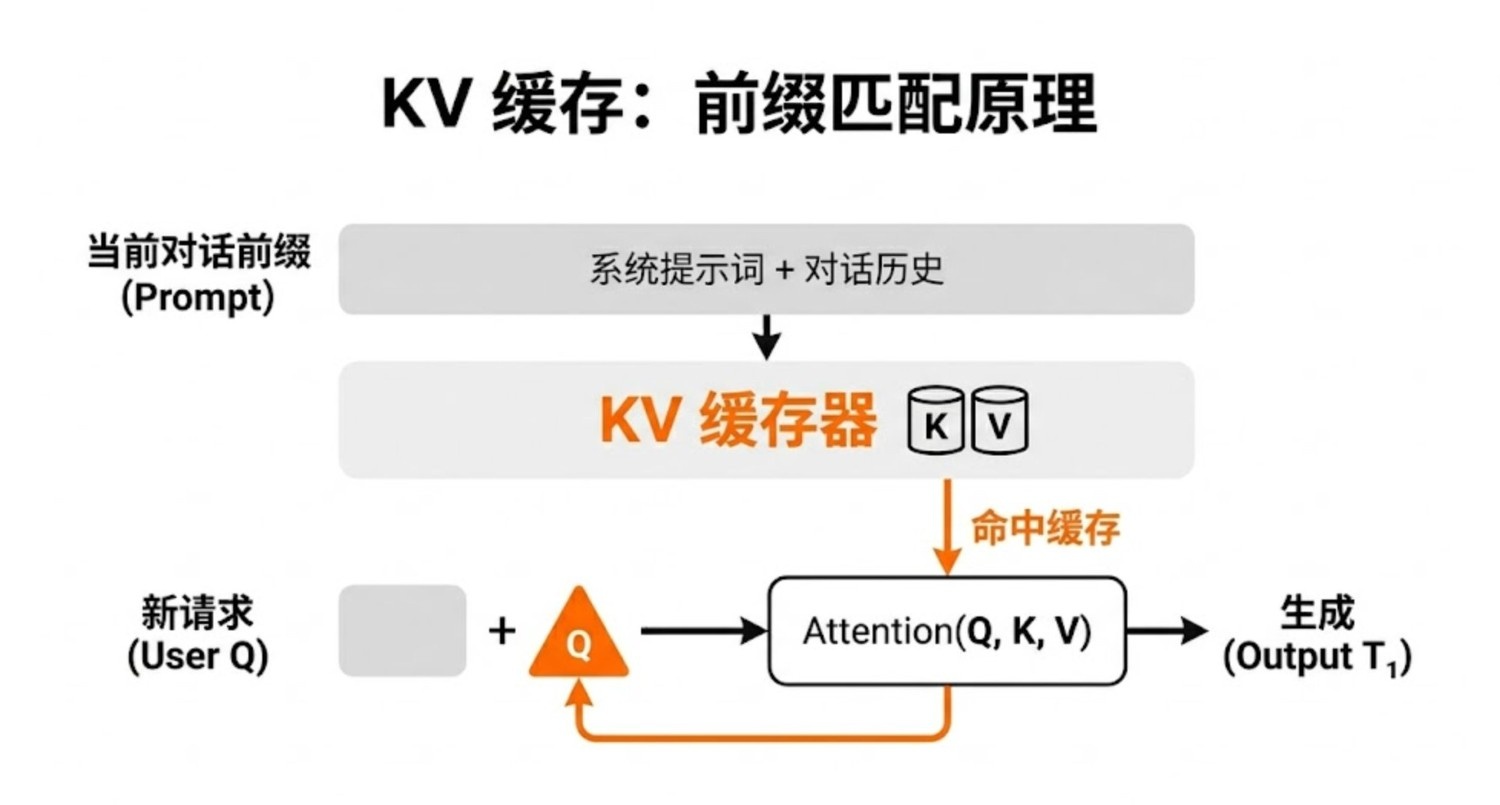
| Q (Query) | 当前新 token -- "我要找什么?" | 每次不同,不能缓存 |
| K (Key) | 历史 token -- "我这有什么?" | 算完就固定,可以缓存 |
| V (Value) | 历史 token -- "具体内容是什么?" | 算完就固定,可以缓存 |
KV 缓存就是把历史 token 的 Key 和 Value 存起来,新 token 只需要算自己的 Q,然后查已有的 KV。
因果掩码 (causal mask):
T1 T2 T3 T4
T1 ✅ ❌ ❌ ❌
T2 ✅ ✅ ❌ ❌
T3 ✅ ✅ ✅ ❌ <- T3 的 KV 永远不变
T4 ✅ ✅ ✅ ✅ <- 新增 T4 不影响 T1/T2/T3
Decoder-only 架构的单向注意力保证了这一点。前面 token 的 KV 算完就固定,后面怎么追加都不影响。

假设:系统提示 20K tokens,每轮对话增加 ~1K tokens
没有缓存(每轮全价):
Turn 1: 20K + 1K = 21K tokens 全价
Turn 2: 20K + 2K = 22K tokens 全价
Turn 3: 20K + 3K = 23K tokens 全价
...
Turn 10: 20K + 10K = 30K tokens 全价
────────────────────────────
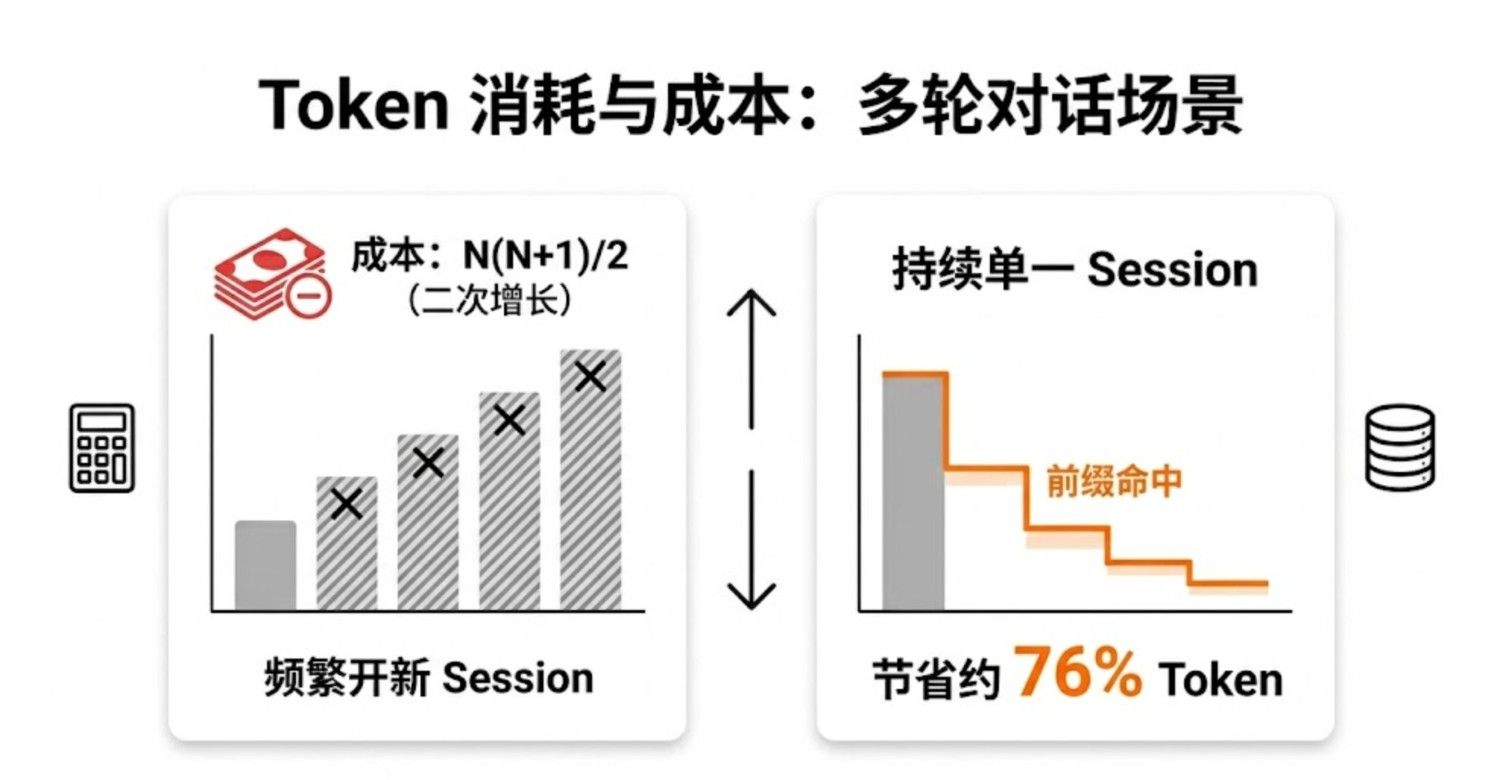
10 轮总计:~255K tokens(全价) <- 二次增长,越来越贵
有缓存(前缀 1/10 价格):
Turn 1: 20K x 1.25 + 1K = 26K 等价 首次写入缓存(贵 25%)
Turn 2: 20K x 0.1 + 1K x 0.1 + 1K = 3.1K 等价 前缀从缓存读
Turn 3: 20K x 0.1 + 2K x 0.1 + 1K = 3.2K 等价 更多前缀被缓存
...
Turn 10: 20K x 0.1 + 9K x 0.1 + 1K = 3.9K 等价 几乎全部缓存
────────────────────────────
10 轮总计:~60K 等价 tokens <- 近似线性增长!
对比:255K vs 60K,缓存省了 76%。
可视化:
没有缓存(每条都全价):
Turn 1: ████████████████████░ 21K
Turn 5: ████████████████████████░ 25K
Turn 10: ████████████████████████████░ 30K
^ 全部全价,面积 = 总花费
有缓存(前缀只花 1/10):
Turn 1: ████████████████████░ 26K (首次写入)
Turn 5: ██░ 3.5K (几乎全缓存)
Turn 10: ███░ 3.9K (几乎全缓存)
^ 前缀淡色 = 缓存读取 1/10
这就是为什么"一个 session 持续对话"比"频繁开新 session"省钱的根本原因。

每次 API 调用,Claude Code 发送的是一个精心拼接的多层结构:
┌────────────────────────────────────────────────┐
│ system(系统提示词,~20K tokens) │
│ Block 1: 计费归因头 -> 不缓存 │
│ Block 2: CLI 前缀 -> 不缓存 │
│ Block 3: 静态指令(行为规则等) -> global 缓存 │ <- 全球所有用户共享!
│ ──── DYNAMIC_BOUNDARY ──── │
│ Block 4: 动态内容(CLAUDE.md 等) -> org 缓存 │
├─────────────────────────────────────────────────┤
│ tools(工具 schema,session 内冻结) │
├─────────────────────────────────────────────────│
│ messages(对话历史) │
│ 最后一条消息上放 cache_control 标记 │
└─────────────────────────────────────────────────┘
关键源码:
// claude.ts:408-413
userEligible =
process.env.USER_TYPE === 'ant' ||
(isClaudeAISubscriber() && !currentLimits.isUsingOverage)| 用户类型 | 缓存有效期 | 条件 |
|---|---|---|
| 默认 | 5 分钟 | 所有用户 |
| 扩展 | 1 小时 | Pro/Max 订阅用户(未超额)、Anthropic 员工 |
5 分钟 TTL 下,停下来喝杯咖啡再回来,缓存已失效。1 小时 TTL 基本消除这个问题。
缓存是前缀匹配。理解这个就理解了一切:
最贵:Block 3(全局静态)失效 -> 整个请求从头算
[❌ Block3] [❌ Block4] [❌ msg1] [❌ msg2] [❌ msg3]
中等:Block 4(CLAUDE.md)变了 -> Block 3 还能复用
[✅ Block3] [❌ Block4] [❌ msg1] [❌ msg2] [❌ msg3]
最省:只追加新消息 -> 前面全部复用
[✅ Block3] [✅ Block4] [✅ msg1] [✅ msg2] [新 msg3]
答案:几乎不能。
主线程 (Opus):
[Block3 ✅] [Block4+tools ✅] [messages ✅] <- 自己的缓存链
Sub-agent (Haiku):
[Block3 ❌ 模型不同] [tools ❌ 工具集不同] [messages ❌ 独立对话]
-> 每次几乎从零开始
每启动一个 sub-agent,基本等于一次"迷你冷启动"。
缓存基于严格的字符级哈希。前缀任意一个字节变化,整个缓存失效。
缓存绑定具体模型。Sonnet 切 Opus,缓存清零。
一个 20,000 token 的系统提示:切模型前每轮 $0.006(读取价),切模型后当轮 $0.075(写入价)。一次切换多付 12 倍。
CLAUDE.md 内容合并在系统提示的第二个断点里。内容改变,整个系统提示缓存立即失效。
做法:开会话前写好 CLAUDE.md,开始后不动。
Claude Code 在系统提示里注入当前日期,但只精确到天。精确到秒的时间戳会让每次请求的哈希都不同,缓存永远无法命中。
如果工具描述里混入了随机 UUID 路径,工具描述每次请求都不同,等于每次都要全价付费。实测是 12 倍的成本惩罚。
生成结果不进 prompt 缓存,但在下一轮对话中被拼回 prompt,自然被缓存覆盖:
第 1 轮:
输入: [系统提示][user: "你好"]
输出: [assistant: "你好!"] <- 不进缓存
第 2 轮:
输入: [系统提示][user: "你好"][assistant: "你好!"][user: "帮我改代码"]
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ~~~~~~~~~~~~~~~~
整段前缀从缓存读取 只有这部分全价计算
对话越长,缓存覆盖比例越高,每轮新增计算量越小。
以 Sonnet 4.6 为例:
| 类型 | 价格 | 说明 |
|---|---|---|
| 正常输入 | $3.00 / 百万 token | 无缓存时的全价 |
| 缓存写入 | $3.75 / 百万 token | 首次建立缓存,贵 25% |
| 缓存读取 | $0.30 / 百万 token | 命中缓存,省 90% |
系统提示通常占每轮输入 token 的 60-80%。只要前缀不变,这部分每轮只付一折。
| 策略 | 说明 |
|---|---|
| 一个会话一个任务 | 话题切换后,旧对话历史变成每轮都要付费的噪音 |
| 主动 /compact | 完成子任务即压缩,附上定制保留指令 |
| 固定模型不中途切换 | 需要换模型就开新会话,保留当前所有缓存 |
| 开会话前写好 CLAUDE.md | 会话中改 CLAUDE.md 等于主动让缓存失效 |
| 策略 | 说明 |
|---|---|
| 一次说完比追问省 | 三条消息 = 三次完整上下文加载 |
| 编辑原始消息 | 不要发新消息纠正,每条新消息永久追加进历史 |
| 给精确路径 | 模糊描述触发 Explore Agent 多轮搜索 |
| 在 CLAUDE.md 里排除大型文件 | JSON 的 token 密度是普通代码的 2 倍 |
| 分段工作 | 把大任务拆成几个独立会话,各自压缩 |
以 5,000 token 的 CLAUDE.md、使用 20 轮对话为例:
| 方案 | 总计 | 节省 |
|---|---|---|
| 有 CLAUDE.md | 首轮写入 + 后续 19 轮读取 = ~0.4 RMB | 90% |
| 无 CLAUDE.md,每轮手工提供 | 20 轮正常输入 = ~2 RMB | - |
Cache 项目将通过 BNB Chain 实现自我可持续发展。
| 机制 | 说明 |
|---|---|
| 缓存优化即挖矿 | 用户使用 Cache 工具优化 token 消耗,节省的 token 按比例转化为积分 |
| 开发者贡献奖励 | 提交缓存策略、优化方案、源码分析的贡献者获得 BNB 奖励 |
| 社区治理 | 持有者投票决定项目发展方向、新功能优先级、资金分配 |
| API 服务 | 缓存分析 API、实时监控面板、自动优化建议 -- 使用 BNB 支付 |
Q1 2026 基础设施搭建 + 源码分析发布
Q2 2026 BNB 智能合约部署 + 缓存监控 API
Q3 2026 开发者贡献奖励系统上线
Q4 2026 社区治理 DAO + API 服务商业化
通过 BNB Chain 的低手续费和高吞吐量,Cache 项目可以将 token 优化的经济价值直接回馈给社区贡献者,形成正向循环。
| 角色 | 链接 | |
|---|---|---|
| MinLiBuilds | 项目发起人 | X |
| IceBearMiner | 核心研究员 | X |
| donglixp | 算法工程师 | - |
| zdaxie | 系统架构师 | - |
1. 保持前缀稳定:固定模型、固定 CLAUDE.md、避免动态内容注入
2. 用好缓存杠杆:把常用上下文写入 CLAUDE.md,10x 折扣从第二轮起生效
3. 控制历史增长:一任务一会话,主动 /compact,批量提问
同样的 Max 套餐,操作习惯不同,实际可用量差距可能在 3~5 倍。
Cache -- 搞懂缓存机制,让你的 Claude Code 套餐多撑 3-5 倍。